
これは何
- 「来年こそはSQL書けるようになるぞ」と思ってる方に向けた、1日1時間・3か月でSQLそこそこできるようになる学習方法について書いた記事です
- 長文がつらつら書いてある本稿ですが、要するに言いたいことは
- なのでご理解いただけた方は本稿をそっと閉じ、下記リンクにて課金! (※Progateさんや著者の木田さんからお金などは何も貰ってません、為念ですが)
ということです。


<Table Of Contents>
- これは何
- はじめに
- 取り組むことになったきっかけ
- 1. LayerXへの転職
- 2. 運営しているECサイトのデータ基盤整備
- 3. Universal Analytics(UA) → Google Analytics 4(GA4)への変更
- 学習前の自分のレベル感
- どれくらいのレベルになるのか
- 身につけ方
- 学習方法サマリ
- 学習時間の目安
- 学習教材について
- オンライン学習
- 書籍
- 自分は合わなかった書籍
- 動画
- PlaygroundとしてのBigQuery
- 超初級編:リトマス紙としてのProgate
- 初級編:「クエリが読み解けない」を突破する
- 中級編:関数のボキャブラリーを増やし、実践で使う
- 中級に上がり、「Excelならこれできるのに><」ができない人へ
- 中央値
- 移動平均
- 加重平均
- ピボットテーブル
- RFM分析
- バスケット分析
- 番外編:クエリの外に出る
- データベースやSQLという言語自体の理解
- データ基盤の理解(Data lake/DWH/Data mart)
- GA4の特徴と仕様の理解
- BigQueryの特徴と仕様の理解
- やらなくていいこと
- 環境構築
- SELECT文以外を覚えること
- 続けるためのメソッド
- やらなきゃいけない状況を作る
- 習慣化 is 正義
- 記録を付ける
- クエリをGitHubで管理する
- もくもく会に参加する
- やってみての気づき
- 取っつきにくそうだが意外と学習コスト低い
- 大人になってからのほうが勉強は楽
- 結局のところ最初は量
- RDBの理解はあったほうがベター
- 「クエリを書けること」以外のメリット
- 正規表現、カラム数、データ型に敏感になる
- 指標の定義に敏感になる
- システムの裏側をイメージしやすくなる
- 頭のリフレッシュになる
- おわりに
- シェアする
- Comment
はじめに
こんにちは!すべての経済活動をデジタル化したいLayerX伊藤です♨ (言ってみたかった)
今年も気づけばあと1ヶ月と少し。ぼちぼち忘年会の予定や、この1年の振り返り的なイベントが入ってきている方も多いのではないでしょうか。
そして年始の目標に掲げていた「今年こそSQLできるようになる!🔥」という過去の自分の宣言と、まったくできるようになっていない現状を比較して自己嫌悪に陥っているBizサイドの人も多いのではないでしょうか。
本稿はそんなあなたに向けた記事になります。
取り組むことになったきっかけ
かく言う自分も今年の春くらいまではまっっっったくSQLできませんでした(今も"できる"とは言い難い…)
前職のReproはRedashを使っていたのでダッシュボードは見ていたのですが、ソースコードには全く触らず。dmemo(データベースドキュメント管理システム)も閲覧はできましたが「ほーん😗」という感じ。
くらいの気持ちでおりました。
そこに、「転職」「GA4の登場」「運営してるECのデータ基盤整備」というトリプルパンチ👊👊👊 が到来し、これはできるようにならねばヤバい、、、ということで学習を始めました。まさに必要は発明の母。
1. LayerXへの転職
まず第一の焦りはLayerX社への転職です。(ちなみに入社しましたポストはこちら)
働き始めているのは11月からなのですが内定は夏にはいただいており、「内定もらったはいいけど、激ヤバエンジニア集団のイメージがあるLayerXで自分は活躍できるのか不安だな~😧」と思っていた矢先にこんな記事が出ました。

LayerXではBizメンバーがSQLを叩くことが日常となっているため、クエリを書いてささっと共有してコミュニケーションをしています。
う…😧
そしてfukkyyさんのTweet。
共通言語的にみんなができるSQL
うう…😧
更には、LXに入るきっかけをくれた野畑君からも。

結構DX部(SaaS事業部)のみなさんSQL使ってる
うわああああ😧
(でもブロックチェーンは必要ないんだ良かった)
…ということで、転職によってお尻に火がついてしまいました。
2. 運営しているECサイトのデータ基盤整備
会社からのプレッシャーの次は事業からのプレッシャーです。
経緯は諸々割愛しますが、LayerX社と兼業の銭湯ぐらしという会社で、この1年半ほどサブスク型のD2C事業をやっております。
細々やるつもりだったのであまり考えずカートシステムをBASEにしたのですが、けっこうな注文数/月商が立っている今でもBASEを使い続けていて大変つらい、移管プロジェクトが絶賛進行中という現状があります。
(BASEは素晴らしいサービスなのですが、如何せんリピート通販向けではないのと今の事業のフェーズに合わず…🥲)
アクセスログやらお客様のアクティビティやらの各種データはスプレッドシートとAirtable(※RDBがシュッと作りやすいSaaS)に溜め、必要に応じてこねくり回して分析&可視化している状態。

カートシステムの移管を考えるにあたり「さすがにデータの集約がスプシとAirtableのままなのはまずい」と気づき、
色々な会社さんのアーキテクチャを見ていたらスタートアップはやっぱりBQを採用しているところが多かったので「銭湯ぐらしでもこれをやろう」ということでBigQueryを触り始めたらここでもSQLが…!
SQLというよりは「データ基盤にはBigQueryが良さそう → BQ使うならSQLマストやんけ😧」という順番なのですが、こちらも自分を焦らせるには充分な動機でした。




3. Universal Analytics(UA) → Google Analytics 4(GA4)への変更
最後は市場トレンドからのプレッシャーです(こちらは1と2ほど強いプレッシャーでも無いですが)
昨年からデジマ界隈を賑わせているHot Topicの一つが「Googleアナリティクス 4(GA4)」だということは皆さん周知の事実かと思います。
この変更も自分は「ほーん😗」という感じだったのですが、SQLよりは取っつきやすく感じたのと、Reproでも話題になっていたり前述のECサイトでもGA4設定せねばだったのでちょこちょこ調べていました。
そうしたら、アクセス分析の大家(たいか)である小川さんや後述する本の著者プリンシプル木田さんはもちろん、マーケ界隈で身近で尊敬している石渡さんなどもGA4とBQ、そしてSQLを一緒に語っているではありませんか。
幸か不幸かGA4の管理画面はめちゃくちゃ使いづらいので、GA4の使い方を新規で覚えるんだったらBQもSQLも一緒に覚えてしまおう、という結論になりました。
要するに「転職」「GA4」「データ基盤整備」の3つがほぼ同時にやってきて
となっていたのが夏ころまでの自分です。
学習前の自分のレベル感
学習を始める前の自分のレベルはこんな感じです。大学の専攻やキャリアの主軸に分析がきたことは一度もない、まあティピカルな文系Biz人材というかんじ。
- ド文系。数学は大学受験で数ⅡBまで。旧帝大レベル
- ちなみに謎の誤解を持たれている方ちょいちょいいますが「数学できるかできないか」はSQL学習にほぼ関係ないです
- Excelはまあできる
- 広告運用レポート / 事業計画 / プロジェクト管理etcの実務
- MOSのExcelエキスパートに載っているようなpivotや統計関数いくつかなどは普通にでき、業務でも経験有
- リレーショナルデータベースへの最低限の理解はある
- EC運用、Reproでの経験
どれくらいのレベルになるのか
ではそんな素人が1日1時間・3か月やったらどれくらいのクエリが書けるのか?
実例を挙げたほうがわかりやすそうなので、書籍『集中演習 SQL入門』の練習問題をいくつか抜粋してみます。
<問題の例>
これくらいであれば、必要に応じてBQの関数リファレンスを見ながらにはなりますが、シュッとクエリで出せるようになります。
上記問題のうち、Q197の実際のクエリはこんな感じ。
<Q197のクエリ>
<Q197の結果テーブル>

(with句2回使ってたりと、自分の回答がスマートな記述なのかは若干怪しい…🤔 ちなみに全ての問題の模範解答はネットに上がってます)
また、5年以上前のかなり古い記事ですが、エウレカさんのTech blog「SQLで分析を始めた人に贈る、中級者に上がるための10のTips 」とかに書いてあるものはほぼすべて理解~実践できるようになります。
まだ「SQL結構できます」などとは口が裂けても言えませんが、少なくともExcelなどと同様に
というレベルにまでは到達できているかなと思います。
身につけ方
ここからは、「じゃあ実際にSQL書けるようになるためにはどう学んでいったらいいのか」について書いていきたいと思います(前置き長くてすみません…)
学習方法サマリ
- 冒頭に書いたこととほぼ同じですが、Progateを速攻で終わらせてからの『集中演習 SQL入門』を隅から隅までやる、がオレ的最速です。
学習時間の目安
「本当に1日1時間を90日間やるだけで出来るようになるんかいな🤔」と不安な方もいるかもなので、上記学習を完了する目安を書いておきます 🗓️
- ProgateのSQLコース:4~6日
- SQLに関する4つのコースの完了目安時間は合計7hと書いてありますが、そんなにかからないかと
- 書籍『集中演習 SQL入門』
- 読むのを5~7日(全8章なので1日1~2章)
- 練習問題の230問を1日3問で70~80日(230 ÷ 3 ≒ 76.7日)
- 後半に行くほど難易度が上がるが前半は楽勝問題ばかりなので、ならして3問/dayという感じ
- その他の書籍や動画
- 空き時間でちょくちょく
どうでしょう、コツコツやれば行けそうな気がしませんか?🧗
学習教材について
サブクエリ、JOIN、ウィンドウ関数など概念的に「🤔?」となるところを攻略したらあとはどれだけ色んな書き方のパターンや関数を覚えられるかのゲームになるので、
- 入門中の入門として一番説明がわかりやすいProgate
- Progateでカバーしていない概念系の説明がわかりやすく、手を動かせる問題が200問以上ある『集中演習 SQL入門』
- 色々なクエリを書いていくにつれて追加で浮かんでくる疑問と、データベースとは何かについての理解を深めてくれる『達人に学ぶ-SQL徹底指南書』
の3つがSQL初心者向け3種の神教材になるかなと思います。
3つすべてに課金(購入)しても6,500円くらい。あとは必要に応じて公式ドキュメント/Qiita/Zennなどをググればわからないところも解消できるので、個人的にはお金払うのはこの3つでよいかなと思ってます。
オンライン学習
- Progate一択でいいかと思います
- 比較していないのでわかりません😇 Udemyとかどうなんでしょうね
書籍
- 何回言うねんという感じですが、『集中演習 SQL入門 Google BigQueryではじめるビジネスデータ分析』が最強です。
- "演習"や"BigQuery"というワードを書いているが故に「他のSQL入門書よりも難しそう…🙁」と誤解されてしまっているのではと思うのですが、普通に各チャプターの構文解説もわかりやすいです。
- 著者の木田さんはGAに関しても『できる逆引き Googleアナリティクス Web解析の現場で使える実践ワザ240』という素晴らしい著書があってほんと凄いなと
- あとは読み物要素が強めですが『達人に学ぶ-SQL徹底指南書』がおすすめ
- 同じシリーズで『達人に学ぶDB設計徹底指南書』があるのですが、こちらは「データベースとは」や「なぜテーブルは分割する必要があるのか」などDBそのものに対する理解が深まるので、読めるようであれば両方読んだ方が良いです
自分は合わなかった書籍
- 『スッキリわかるSQL入門 第2版 ドリル222問付き!』
- パラ読みしかしていないですが、大半の内容はProgateでカバーしてそうと思います
- この本が用意している「dokoQL」という環境を使ってやるのですが、これだったらProgateにも同じ環境あるなと
- あとこれはProgateもそうですが、
select 出金額 from 家計簿のようにサンプルで出てくるテーブルのカラム名が日本語なのが自分は違和感ありました… 😗 - 『ソフトウェアデザイン 2017年 11 月号 [雑誌]』
- 非エンジニアが気づいたらSQL書けるようになった話@BASEで紹介されていたので買ってみましたが、本号目玉の「SQL50本ノック」は量も実践との近しさも『集中演習 SQL入門』に及ばず、買ってパラ読みしてすぐやめました🙁
- あと(演習だけなので当然ですが)環境構築は読み手にお任せ、というのも初心者にはちょっと敷居が高いのかなと思います
- 『10年戦えるデータ分析入門』
- Gunosyテックブログなどをはじめ、よくSQL始めるための入門として紹介されていますがまだ読んでいません😇 良い本とは聞いたので、いつか読んでみる…
動画
SQL自体を動画で学ぶことは無かったのですが、データベースとBigQueryの学習に関しては本やGoogleの公式ドキュメントよりも動画でわかりやすいものがいくつかあったのでちょいちょい観てました。
- データベースの話
- 何本か違う人のYouTubeを観て、個人的にはこれが一番わかりやすかったです
- BigQueryの話
- Data Engineering Study #6「改めて学ぶ、BigQuery徹底入門」のGoogleの方の講演がめちゃくちゃわかりやすいです。
- これ以外も Data Engineering Studyの勉強会動画は面白いので他のも観てみるとよいかと
- [Cloud OnAir]BigQuery ML と AutoML Tables ではじめるマーケティング分析入門[2019年5月23日放送]など、Google Cloud Japanの公式動画もわかりやすいです。

動画は英語だともっといっぱいありそうです。
PlaygroundとしてのBigQuery
前述の通り、概念系の「🤔?」をひと通り理解したらあとは手を動かすのみ!なのですが、そこでとってもありがたいのがBigQuery。
文法に多少差異があるので自社でRedashやMetabeseがデファクトになっている場合はそちらをPlaygroundとするでも良いかなと思いますが、
本稿で推している『集中演習 SQL入門』はBigQueryを前提とした書籍になっているので特に制約がなければBQで良いかなと。
超初級編:リトマス紙としてのProgate
ここからは、この学習方法を進めるにあたっての躓きポイントや所感などを書いていこうと思います。(超初級〜中級のレベル感は完全に自分の独断と偏見です)
再掲
まずは超初級編としてのProgate(プロゲート)から。
Progateに関しては、「そもそも自分はクエラーとして適性があるのか」を測るリトマス試験紙としてとりあえずやってみるのが良いと思います。
おそらくSQLのコースI~IIIまでひと通りやってみたときに躓くのは
- whereとhavingの使い分け
- distinct
- サブクエリ
- JOIN
あたりだと思いますが、1周目はともかく2~3周やってみても分からなかったら教材としてのProgateがどうこうという話ではなくおそらく根本的に向いていないので、
「自分は向いていないんだな」と諦めたほうが良いかなと思います。人生、諦めも肝心 😇
逆にここで「楽し~!」となったりSQLZOOとか他サイトの問題をProgate側で書いてみたりする気持ちがあれば、このあともやり切れる可能性が高いです。
初級編:「クエリが読み解けない」を突破する
Progateが終わったら、神教材その2にして90日間の学習のほとんどを費やすことになる『集中演習 SQL入門』に入っていきます。
ちなみにProgateで学ぶことはこの書籍もすべてカバーしているので、いきなりこの書籍から始めてもいいと思います 📔
Progateやってからすぐに会社のエンジニアが書いているクエリの写経などで学ぼうとすると爆死するので、この書籍の各チャプターで下記の構文を覚えていきます 📝
- if文とcase式 (条件分岐)
- 色んな所に出てきますが、Excelのif文と基本変わらないです。
- JOINの色んなパターン
- ProgateではJOINとLEFT JOINだけしか出てこないのですがSELF JOIN や CROSS JOIN も覚えましょう。
- あとテーブル結合には onではなくusingも多く使うので覚えましょう。
- UNION
- 横につなぐJOINに対して縦につなぐUNION。
- ベン図で覚えるのが良きです🌜
- サブクエリ
- Progateでも出てくるが本当に色んなパターンがあるので、この書籍で手を動かして学ぶ。自分もここが未だに一番苦手…
- with句(仮想テーブル)
- 複雑なクエリを綺麗にしてくれる便利なwith。サブクエリで入れ子にするものの多くはwith句のほうが見やすくなるケースが多いです。
- 自分も結構with句に逃げがちなのですが、BigQueryについては一時テーブルのほうがいいらしいです。慣れなきゃ…😧
- window関数
- OLAP関数とか分析関数とか色んな名前があってややこしいのと書き方が特殊なので慣れないうちは難しく感じますが、慣れてしまうと便利です。
- OVERはwindow関数を使いますよーというサインです。
- 移動平均やnth_valueなど、このあたりから単純なデータ抽出やクロス集計の域を超えてくるので「Excelより便利だわ~い」となります。
- (BigQueryを使う場合) UNNEST
- BigQueryでGA4のデータを扱うなら避けて通れないUNNEST。
- これも学習開始後にしばらく経って「結構クエリ書けるじゃんオレ😎」と調子乗ったタイミングでGA4のテーブル見ると何もわからず爆死するので、なぜこういうテーブル構造なのかというところも含め勉強しましょう。
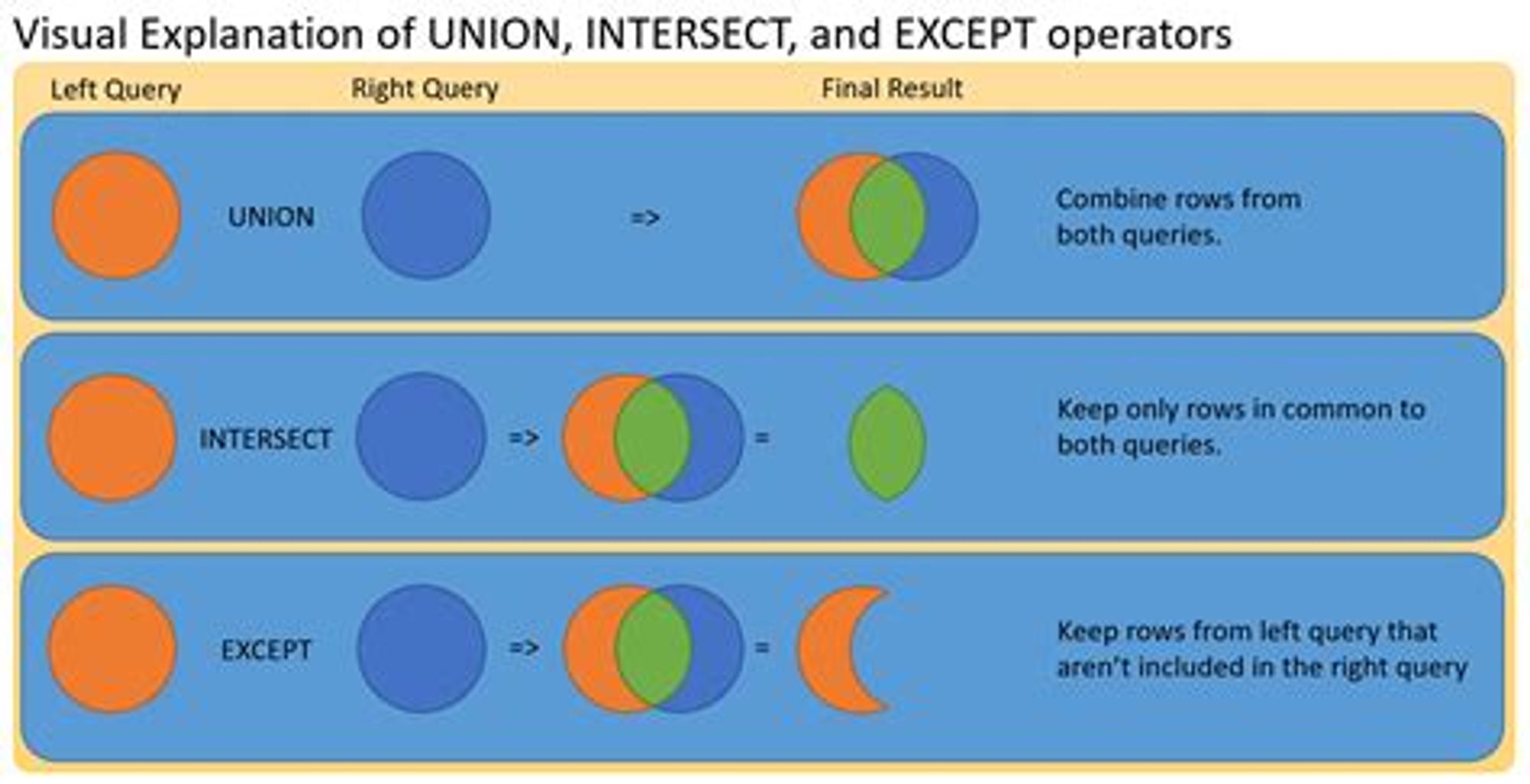


ここまでひと通り終えると、関数単位でわからない(知らない)ところはまだまだ沢山出てきますが、他の人が書いたクエリを読んで「何がどうなってんだこの書き方??🤔🤔」と文法から理解不能になることはまずなくなるはずです。
英語学習でいうと、時制や仮定法、SVOCなど5文型をひと通り覚えてあとは単語やイディオムの蓄積を増やしていく段階と同じ感じ?(適当)
中級編:関数のボキャブラリーを増やし、実践で使う
書籍『集中演習 SQL入門』の各チャプターを1周したら上記で挙げた文法はひと通り修了するので、あとは100本、いや、230本ノックです⚾
練習問題に取り組む過程で、
- 数値変換系の関数
- 四捨五入したり変換(cast)したり
- 日時変換系の関数
- タイムゾーン直したりクオーターごとにまとめたり
- 文字列変換系の関数
- 文字列つなげたり数えたり抜き出したり
- 正規表現
- urlのパラメータとったり👆より柔軟に文字列置換したり
など実務で当たり前に出てくる関数を何度も書くことになるので、最初はBQの関数リファレンスを何度も見ながらになって時間かかると思いますが、繰り返しやって自分の血肉にしましょう🍖🔥
また、この段階まできていて、実務で沢山クエリを書く機会がある方は無理に230問すべてをやる必要は無いと思います。
BigQuery、Redash、Metabeseなどなど各々に用意された環境で頑張りましょう〜
中級に上がり、「Excelならこれできるのに><」ができない人へ
- ある程度書けるようになっても、「これExcelでやったら秒なのに😕」というのが出てくると思います。改めてExcelって色んな関数や分析機能が標準実装されていて凄いツールだな~と
- そんな方のために、逆引き的によく使いそうなものを書いておきます。
- クエリは該当の箇所の抜粋で全文ではないのでご留意ください。
中央値
- MEDIAN関数あると思うじゃないですか?無いんですよ🙄
- 覚えにくいかもですがPERCENTILE_CONT関数を使えばできます。
0.5のところは可変なので0.25などにすれば四分位数もとれます。
--男女別の年齢の平均値と中央値
if(gender = 1,"男性","女性") as gender
,avg(
datetime_diff("2021-12-31",birthday,year)) over(
partition by gender
) as avg_age
,percentile_cont(
datetime_diff("2021-12-31",birthday,year),0.5) over(
partition by gender
) as median_age移動平均
- 前述のwindow関数で
avgを使えば簡単にできます。
--前後1ヶ月を含めた移動平均
avg(sum_rev) over(
order by year_month
rows between 1 preceding and 1 following
) as moving_avg_rev 加重平均
- Excelだと「SUMPRODUCT関数」使って一発で出せるやつですね。前職入社当初、加重平均を知らなくて算術平均で出したら上司にボコされた淡い思い出。
- sum内で"重み×数量"を掛けて数量で割ればスッと出ますね。
--価格×数量の加重平均
select
avg(revenue) as average
,sum(revenue*quantity)/sum(quantity) as weighted_average
from sample.sales`ピボットテーブル
- いわゆる「縦持ち」を「横持ち」にするってやつですね。これもExcelだとよーく使いますが、Bigqueryでも今年の5月にPIVOT関数が出ました。
- 書籍『集中演習 SQL入門』刊行時点では無かった関数なので、Googleの公式ブログなど見て書き方を覚えましょう。


RFM分析
- Recency(直近いつ)、Frequency(頻度)、Monetary(購入金額) の3次元でセグメント作るやつです。
- それぞれOLAP関数で下記を使い、出したテーブルに対してデシルで使った
ntile()を使えば割とすぐ出せます。 - Rは
first_value()(ないしlast_value()) - Fは
count() - Mは
sum()
バスケット分析
- 「ビールを買っている人はオムツも一緒に買っている」みたいなやつです。『集中演習 SQL入門』でもp208に少しだけ出てきます。
- 慣れないと概念的にやや「🤔?」かもですが、同じテーブルを分身させて結合する自己結合(self join)するとできます
番外編:クエリの外に出る
- 番外編として、クエリ230本ノック以外にもやるといいことをつらつら書いてみます。
- 本パートに関してはもっといい方法や「これもやっとく/読んどくと良いよ」というのが沢山ありそうなので、ご存知の方はぜひ教えてください🙏
データベースやSQLという言語自体の理解
- 50~100本くらいクエリ書いたあとで、『達人に学ぶSQL徹底指南書』『達人に学ぶDB設計徹底指南書』の2冊を読んでみましょう。
- それでも全体の5~6割くらいしか理解できないかとは思いますが(自分はそうだった)、
- データベースというものがそもそもなんなのか
- なぜウィンドウ関数はonじゃなくてoverなのか
- RDB近現代史
- データベースのパフォーマンスを決める要因
- 2冊とも普通に読み物として面白いので、クエリ書くのに疲れた合間にちょくちょく読み進めるのがいいかと思います。
- あとこの2冊に書いていないが概念系で重要そうなものでいうと「行指向データベース」「列指向データベース」があるので、オプトさんの各種データベースの特徴とパフォーマンス比較のスライドなど読んでキャッチアップすべしです。
といった、今までの学習でふわっと理解していた概念や素朴な疑問を書いてくれているので、読むとより多面的な理解につながります。
データ基盤の理解(Data lake/DWH/Data mart)
- SQLが書けなくても、デジマ界隈の方々は「データレイク」「データウェアハウス」「データマート」について一定の理解はあるかと思います。
- SQLやBQを触った状態で改めて「この3つの違いは何ぞや」というのを学ぶと、理解が深まります。
- ググれば色々出てきますが、「Data Engineering Study #1」でゆずたそさん(@yuzutas0)がとってもわかりやすく話しているので、まずはこれを観るだけでも十分かもです。
- 書籍だとUNCOVER TRUTHさんが出している『ユーザー起点マーケティング実践ガイド』もCDP(Customer Data Platform)観点でlake,ware house,martについて書いているのでお勧めです。
- あとゆずたそさんの書籍もいいらしいです(まだ読んでない)


- 他にこのあたりの記事もおすすめです。
- BIツールとDWHの役割分担
- 分析者から見た使いにくいデータ基盤の話
- データ基盤にありがちな「何を使って作ればよいか?」という問いに対する処方箋を用意してみました.



GA4の特徴と仕様の理解
- UNNESTの話もちろっとしましたが、実務でSQLを扱う際のデータソースがGA4やFirebaseの方は多いかと思います。
- データ分析界隈の方もいろいろ苦戦されているように、GA→BQにイベントの送られるタイミングやワイルドカード(_table_suffix)など結構クセが強いのと、情報が日々アップデートされていくので公式Docを追う + 界隈の方々の発言を追う、でキャッチアップ頑張るべしです。
- 「GA4のpage_viewイベントはスクリプト読み込み後5秒後に動く?」など知らなきゃわからん仕様がいっぱいあります
- Firebaseも吐き出されるログの形式はGA4と同じのようですが、自分がほぼ触っていないので割愛します。
BigQueryの特徴と仕様の理解
- BigQueryも普通にクエリ書いてる分には「便利だな~」くらいにしか思いませんが、歴史を紐解くとDWHとしても他と比べて異質な存在であることや、よくエンジニアが「BQは"速い"」と言っている意味がわかってきます(本当に何となくですが…)
- BQも概要についてはData Engineering Study #6「改めて学ぶ、BigQuery徹底入門」のGoogleの方の講演がわかりやすいです。

- 他にこのあたりの記事もおすすめです。
- [初心者向け] Google BigQueryの基礎を理解してGoogle Cloud Consoleから触ってみた
- グーグルのBigQuery、高速処理の仕組みは「カラム型データストア」と「ツリー構造」。解説文書が公開
![[初心者向け] Google BigQueryの基礎を理解してGoogle Cloud Consoleから触ってみた | DevelopersIO](https://images.spr.so/cdn-cgi/imagedelivery/j42No7y-dcokJuNgXeA0ig/ff157f69-2b3e-41f8-a742-97e2d0359636/gcp-eyecatch-bigquery_1200x630/w=1920,quality=90,fit=scale-down)

- あとこちらも情報が日々アップデートされていくので公式Docを追う + 界隈の方々の発言を追う、でキャッチアップ頑張るべしです。
- BQに関しては書籍も色々ありそうですが、読めていないですm(__)m
やらなくていいこと
環境構築
- 環境構築はまずBizサイドが行うことは無いので、やらなくていいでしょう。これが要らないのがBigQuery(以下略
SELECT文以外を覚えること
- SQLには4大命令というのがあり、「SELECT、UPDATE、DELETE、INSERT」のうちこれまで扱ったのはSELECTのみです。
- ProgateのSQLコースでもデータの追加・更新・削除を学ぶパートはあるのでサラっとやってみるのは全然アリですが、構文は一周したくらいだとすぐ忘れるので個人的にはやらなくていいかな〜と思います。

続けるためのメソッド
急に自己啓発本感あふれるパートですが、今後もどんどん新しいことを学ぶ必要に駆られるであろう将来の自分に向けた備忘録として続けるためのコツを書いてみます。
やらなきゃいけない状況を作る
- きっかけのパートで書いた通り、自分は完全にこれでした。追い込まれないと頑張れないタイプ😇 環境を変えるのが手っ取り早いですね~。
- 逆に、本稿の通り3か月位である程度できるようにはなるので、今できなくても何とかなっている人は無理にやらなくても良いのでは、と思います🐶
習慣化 is 正義
- 何においてもそうですが、習慣化は本当に正義だなと思いました。自分の場合はコロナ禍で朝型にシフトしたのも要因として大きいです。モデルナワクチンの副反応で死んだ1日を除いて、毎日ほぼ欠かさずに続けられました。
- 幸い『集中演習 SQL入門』は多様な練習問題が沢山あるので、「朝の6時半~7時半で1日3問やる」という超シンプルな原則だけ作ってそれに従っていれば自ずとレベルが上がっていくという風にできたのが良かったです。
- もちろん時間通りに取り組めなかった日もありますが、どんなに眠くても忙しくても最低限
select hoge fuga
from customer_table
limit 100くらいの超簡単なクエリは書いてBQのコンソールを開かない日をゼロにする。「1日休むと取り戻すのに3日かかる」というのは迷信といわれてますが自分は一定正しいと思います。
記録を付ける
- このあたりは完全に学習スタイルの話ですが、自分はゴールまでどれくらいのペースで行けばいいのか、あとどれくらいなのかなど見えているほうがモチベーションが続きやすいので「問題の完了予定日」と「実際に終わった日」などを書いてちまちま進めていました。
- フルマラソンのペースメーカーみたいなイメージです🏃

クエリをGitHubで管理する
- これは未だにどういう方法が良いのかサッパリわかっていないのですが、230問のクエリを全てBQに保存するのもアレなのと、
- BQ上では複数のクエリ間を
Cmd+Fで検索できなくて「このQ180の問題、Q95あたりでも似たクエリを書いたような…」というときにパッと検索できないので、一つのファイルにバーッと解いていったクエリを書いてファイル上でCmd+Fし、差分を一人プルリクエストしてます。

もくもく会に参加する
- 自分は試しに1週間ほど参加してみて特に集団学習効果が無くてもできそうだったのでやってないですが、こういう朝活/夜活のDiscordが何個かあります。

- Studyplusとかもあるので独りだと続けられなさそうという人は入ってみてもいいかもです。
やってみての気づき
まだ3~4か月ほどですが、やってみての気づきなどを書いてみます。
取っつきにくそうだが意外と学習コスト低い
- プログラミングと混同されて「非エンジニアには難しいのでは…」という謎の誤解があるような気がしますが、データベース操作言語なのでExcelなど使っている人であればぜんぜん取っつきづらくないうえに、学習コスト低いです。
- 資格試験と比べるのもアレですが、
らしいです。本稿が示す3か月で1日1時間ちょっとのSQL学習は合計100時間位なので、上記2つの資格を取る半分以下の学習コストとなります。
もちろん暗記物の要素が強い資格試験とSQL学習を一概には比べられませんが、参考までに🙏
大人になってからのほうが勉強は楽
- 本稿をお読みになっている人で「ExcelもGoogleフォームも一度も触ったことがない」という人はおそらくいないと思います。GA触ったことが無い人も少ないでしょう。
- ということは今までの業務で何かしらデータベース的なものを扱ったことがあり、SQL学習の過程で「BQのこの関数はExcelのこの関数と一緒だな」「アンケートフォームの選択式と自由記述はデータ型の指定をしていたのか」など普段の業務とのメタ認知を効かせることができると思います。
- 自分自身もそうでしたが、そうするとまっさらな状態から学ぶよりもずっと理解の深まりが早いです。経験は糧になりますね 💪
- ご家族や仕事の兼ね合いなどで時間の捻出が大変な方も多いと思いますが、まあそれは何においてもそうなのでやると決めたならやるしかないですね🦌
結局のところ最初は量
- 新しいことのキャッチアップ全般に言えることですが、最初はつべこべ言わず量をやるのが正解だなと改めて思いました。
- 本稿もお勧めの学習方法などを挙げさせていただいてますが、結局は演習の230問をやりきれるかどうかが分かれ目なので、とりあえず騙されたと思ってやってみてください。
RDBの理解はあったほうがベター
- 本稿の前のパートでも書いてますが、リレーショナルデータベース(RDB)の理解が浅い方はSQL学習にあたって一緒に勉強しておくのが吉です◎
- 特に練習問題の整えられたテーブルを使ったselect文だけしかやらないと、実務で「このテーブルはどうやって作られているのか」「テーブル間を繋げる(JOIN)には何を外部キーとしたら良いのか」というところに思いをはせることが出来ないかと思います。
- なのでインプットとして学習教材のパートで挙げたような動画や書籍『達人に学ぶDB設計 徹底指南書』を読んだり、Googleフォーム + Airtableとかで簡易なRDBを自分でシュッと作ってみるのもおすすめです。
- 若干気合いは必要ですが、EC運営などスモールビジネスやるのも激おすすめです!SQL、RDBに限らず色々気づきを得ます。特にB2B畑の方などはB2C新鮮で楽しいと思います💐
「クエリを書けること」以外のメリット
最後に、データベース言語としてのSQLを学ぶことによることによる副次的なメリットを書いてみたいと思います。
正規表現、カラム数、データ型に敏感になる
- 「Excelやアンケートフォームなどを業務で使っていればメタ認知を効かせることができる」と書きましたが、逆もまた然りです。
- SQLを学習することによって、今まで文字列で書いていた日付を日付型に変換しようという気になったり、人によってアンケートフォームの姓名を分ける人(2カラム)とフルネームの記入欄を設ける人(1カラム)がいることにイライラしたりすることがあると思います。
- そういうところに気が回るようになれば、たとえSQLを使わなくても業務にきっと良い影響があるかと👍
指標の定義に敏感になる
- 特にGAを普段触っている方は、BQを経由してGoogleデータポータルなどでkpiを可視化する過程で
- GA4のGUI上でポチポチやるのも便利ですが、GA4はイベントやらパラメータやらプロパティやら初見で分かりづらく感じるものもあると思うので、より理解を深める意味でもBQに吐き出されるログから見るのお勧めです。
などなど、今までGoogleアナリティクスでぼんやり見ていた指標がどういうロジックで管理画面に表れているかがわかるようになります 📊
システムの裏側をイメージしやすくなる
- これもクエリ書いてるだけだと身に付きにくいかもしれませんが、自分でER図を書いたりAirtable触ったりすると「なるほど、こういうビジネスモデルのサービスだとこういうテーブル構造が必要なんだ」というのがぼんやりわかってきます。
- HubSpotしかりSmartHRしかり、SaaSなんて特にRDBのかたまりなので、考え方として身に付くと何かと役に立ちます。
- 財務分析やられてる方やSalesforceアドミンの方などは、このあたりの思考が実務で自然と身についている勝手なイメージです。
頭のリフレッシュになる
春先にやっていた『大豆田とわ子と三人の元夫』観ましたか?最高のドラマでしたね…
というのはさておき、劇中では主人公のとわ子(松たか子)が夜な夜な数学の問題集を解くシーンが描かれていました。
観ていたころは特に気に留めていなかったのですが、当該シーンの考察を読んで「自分がSQL学習に感じていた効果もこれだ!」と膝を打ちました。
細かいですが、該当のシーンで問題が解けたときに、とわ子が、モヤモヤが晴れたようにハッと目を見開くような瞬間がありました。 つまり、解決策が見えない問題に悩んでいるときに、数学の問題という「論理的に1つの解を導き出せるタスク」に取り組むことで、頭をリフレッシュしているのではないかとも読み取れます。 (『『大豆田とわ子と三人の元夫』に見る!参考書・問題集が「演出」するとわ子のキャラクター』より抜粋)
特にBizサイドの日々の業務や意思決定は「100%正しい」ことが無いものも多く、何らかのトレードオフや交渉が少なからず発生します。
そんな白か黒かで語れない問題に脳が疲弊してしまったときに15分でもSQL書くと、ものすごく頭がスッキリします。すぐできるリフレッシュ方法としておすすめです。
おわりに
だいぶ長くなってしまいましたが、1日1時間を3ヶ月継続でどれくらいの知識が身につくか、クエラーとしてどれくらいのレベル感になるか、クエリが書ける以外のメリットは何か、などをなるべく網羅的に書いてみました。
というわけで、LayerXはラーニングアニマルにとってはとっても良い環境です!
SQLはほんの一例で、他にも身につけなければいけないこと転がりまくりで楽しいです~ 🐼
ちなみに今はSQLよりデザインツールの「Figma」を覚えなければいけなくなったので頑張ってますです…
マーケやセールスはじめ積極的に募集しているので、興味がある方は一度お話しましょう。

SQL学習に詰まったら『大豆田とわ子』観ましょう。めちゃくちゃ面白いです。「人生とは」という感じがします。

それでは今年もあと少しですが、頑張っていきましょう 💪